








“What are the best open source models today? They’re Chinese,” famous entrepreneur and investor David Friedberg said on the All-In Podcast he co-hosted in June.
He’s right. But the best open models being Chinese isn’t the interesting part. The interesting part is how much developers are becoming dependent on them – and the usage data shows a market splitting cleanly in two.
Start with one number that should stop you. Claude Opus 4.8 ranks around #1 on intelligence benchmarks. On OpenRouter, it ranks around #7 by actual usage.
What OpenRouter actually tells you
OpenRouter is a marketplace for tokens. A developer plugs in once and routes workloads to whichever model they like – switching between DeepSeek, Claude, Gemini and dozens of others on price, speed, or quality.
Although OpenRouter represents probably only around 1% of the world’s total token usage, it is often seen as a useful proxy of what developers vote with their wallets.
Here’s the Top 10 most used AI models on OpenRouter as of 25th June.
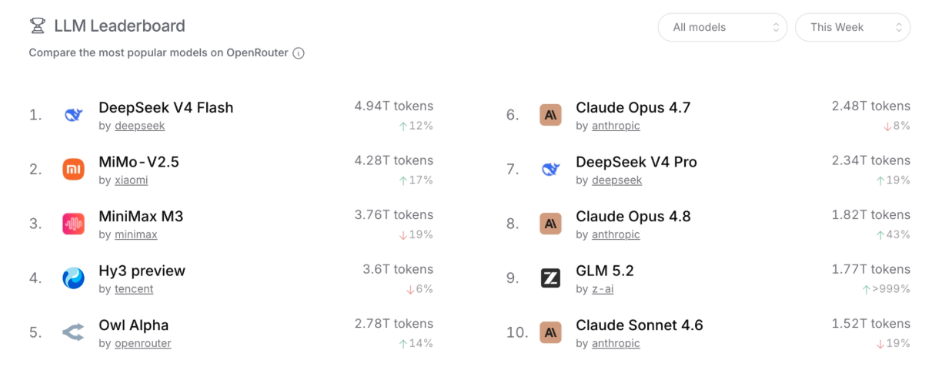
We can see that Chinese-developed models take up 6 out of the 10 spots on the leaderboard. Amongst the 6 LLM companies which developed these models, 5 are Chinese with Anthropic being the only U.S. lab on the board.
DeepSeek is particularly impressive here. Its two models, DeepSeek V4 Flash and DeepSeek V4 Pro, together handle more usage than Anthropic’s models on the platform, on the order of 7.2 trillion tokens to 5.9 trillion.
But the stronger signal is not that DeepSeek is number one this week. It’s more important to look at the shape of usage over a period of time. We compared the usage of Deepseek vs MiniMax vs Anthropic from March – June:
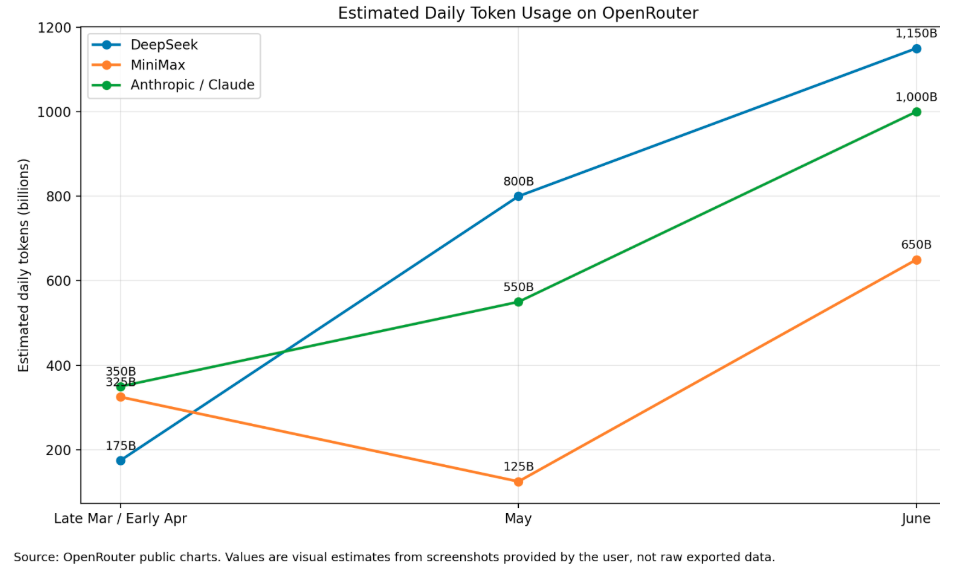
What this shows is that Deepseek usage has climbed consistently and then stayed elevated. Developers are not just trying it once; they are routing work through it repeatedly.
Comparatively, we see Minimax usage dipping in May, but having a sudden surge when a new model is launched in June. This is more indicative of users trying and testing a new model (which also often offers more competitive pricing at the release).
This is why DeepSeek isn’t just a normal leaderboard winner. It looks closer to a reliable choice: cheap enough to use at scale, good enough not to be swapped out, and open enough to sit inside other people’s stacks.
So how is DeepSeek able to become so popular? The price is obviously a big lever here.
Here is a table showing the price of DeepSeek’s official API pricing against Anthropic’s offerings:
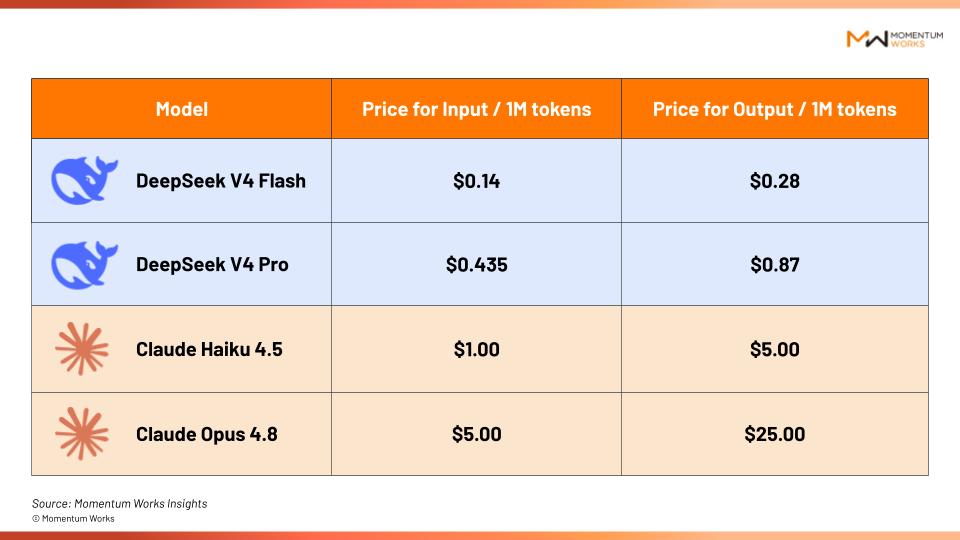
As you can see, Anthropic’s tokens cost 7-28 times those of DeepSeek.
Claude still wins the premium work: complex reasoning, high-stakes decisions, regulated industries, and cases where being wrong is expensive. But the vast middle of AI usage may not need the most powerful model. It needs something good enough, reliable enough, and cheap enough to call again and again.
In that regard, DeepSeek is a good enough, and consistent, choice.
We also heard that at this price point, DeepSeek still generates a decent gross profit on token usage.
Who should actually be worried
The question is – is value for money a deliberate choice of DeepSeek? Is it capable of building Claude-quality models and choosing not to do so?
In many other sectors (platforms in particular which we cover a lot), you see the players building scale through lower cost offerings eventually being able to challenge the premium competitors effectively. Does the same apply to AI models?
The smartest model wins the benchmarks. The good-enough-and-very-cheap model wins the volume. Would they converge in competition?






